
联系:QQ(5163721)
标题:一次数据库性能问题处理(11g自动维护任务,log file sync)
作者:Lunar©版权所有[文章允许转载,但必须以链接方式注明源地址,否则追究法律责任.]
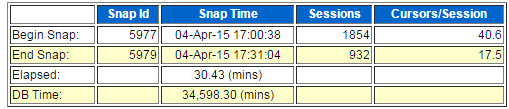
看到问题发生前30分钟的awr显示,系统负载超高:
查询数据库当前等待事件:
SQL> set pages 999
SQL> set linesize 1000
SQL> SELECT inst_id,event,count(*) FROM gv$session WHERE wait_class#<>6 group by inst_id,event order by 1,3;
INST_ID EVENT COUNT(*)
---------- ---------------------------------------------------------------- ----------
1 DBWR slave I/O 1
1 enq: TX - row lock contention 1
1 db file parallel write 1
1 asynch descriptor resize 1
1 read by other session 1
1 log file sync 3
1 direct path write temp 3
1 db file sequential read 6
1 enq: TX - index contention 193
1 resmgr:cpu quantum 226
1 buffer busy waits 822
11 rows selected.
SQL>
跟awr中的信息一致:
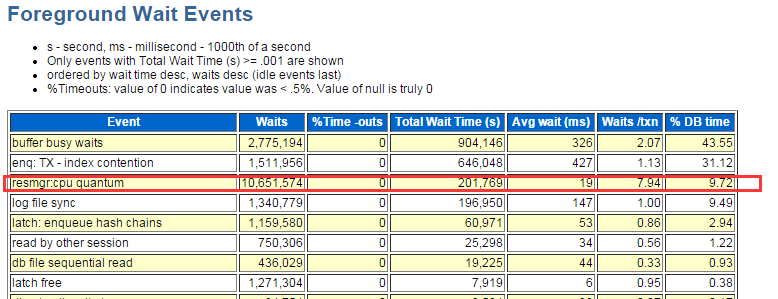
直觉是resmgr:cpu quantum引起了其他一系列问题,这个已经不是第一次遇到了。
等待事件 resmgr:cpu quantum 是11.2引入的oracle资源管理引起的,这个东西一般问题很多,大部分时候,我们装机时,都是直接禁用的。
11.2的oracle资源管理中有一项最坑的是周末的维护任务,这个遇到好几次了。
禁用方法:
1,关闭一些不需要的维护任务:
exec dbms_scheduler.disable( 'ORACLE_OCM.MGMT_CONFIG_JOB' ); exec dbms_scheduler.disable( 'ORACLE_OCM.MGMT_STATS_CONFIG_JOB' );
关闭数据库的空间Advisor,避免消耗过多的IO:
BEGIN DBMS_AUTO_TASK_ADMIN.DISABLE( client_name => 'auto space advisor', operation => NULL, window_name => NULL); END; /
关闭数据库的SQL自动调整Advisor:
BEGIN DBMS_AUTO_TASK_ADMIN.DISABLE( client_name => 'sql tuning advisor', operation => NULL, window_name => NULL); END; /
关闭数据库的weekday窗口的DEFAULT_MAINTENANCE_PLAN:
alter system set resource_manager_plan='' scope=both;
execute dbms_scheduler.set_attribute('WEEKNIGHT_WINDOW','RESOURCE_PLAN','');
execute dbms_scheduler.set_attribute('WEEKEND_WINDOW','RESOURCE_PLAN','');
execute dbms_scheduler.set_attribute('MONDAY_WINDOW','RESOURCE_PLAN','');
execute dbms_scheduler.set_attribute('TUESDAY_WINDOW','RESOURCE_PLAN','');
execute dbms_scheduler.set_attribute('WEDNESDAY_WINDOW','RESOURCE_PLAN','');
execute dbms_scheduler.set_attribute('THURSDAY_WINDOW','RESOURCE_PLAN','');
execute dbms_scheduler.set_attribute('FRIDAY_WINDOW','RESOURCE_PLAN','');
execute dbms_scheduler.set_attribute('SATURDAY_WINDOW','RESOURCE_PLAN','');
execute dbms_scheduler.set_attribute('SUNDAY_WINDOW','RESOURCE_PLAN','');
Commit;
查看当前active的resource plan ,确认已经关闭:
SQL> select * from v$rsrc_plan;
ID NAME IS_TO CPU INS PARALLEL_SERVERS_ACTIVE PARALLEL_SERVERS_TOTAL
---------- -------------------------------- ----- --- --- ----------------------- ----------------------
PARALLEL_EXECUTION_MANAGED
--------------------------------
12540 INTERNAL_PLAN TRUE OFF OFF 0 64
FIFO
SQL>
此时awr可以看到系统负载已经下降一点点,但是依然很高:
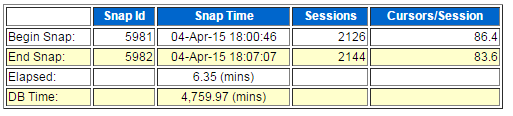
上述修改后的数据库等待事件已经变味“log file sync”,具体如下:
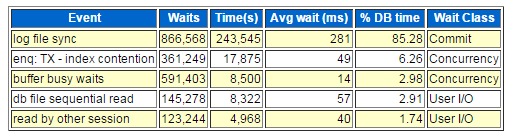
相应的前台等待事件:
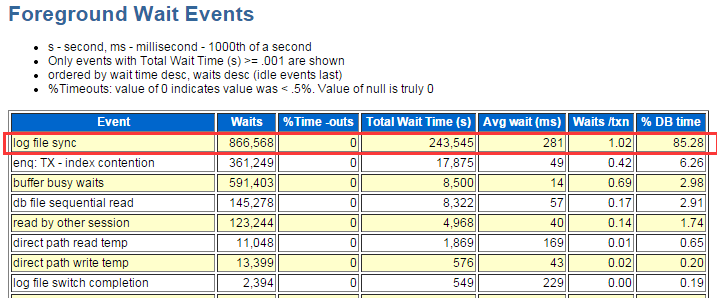
后台等待时间:
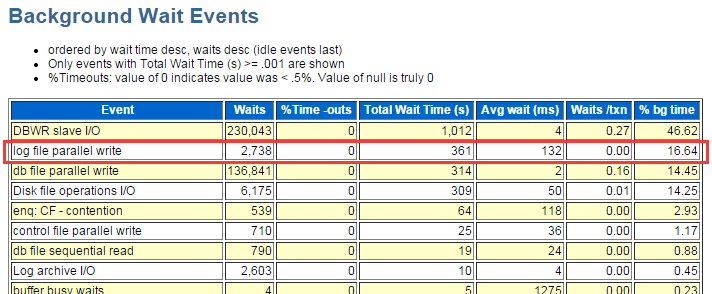
在LGWR的trace中,可能会出现类似如下的信息:
kcrfw_update_adaptive_sync_mode: poll> post current_sched_delay=0 switch_sched_delay=154 current_sync_count_delta=887 switch_sync_count_delta=837
这是11.2的新特性,Adaptive Switching Between Log Write Methods(LGWR写模式自动切换),该功能bug一堆,经常导致commit缓慢而带来的“log file sync”。
通过设置如下隐含参数,禁用11.2这个LGWR写模式切换功能:
ALTER SYSTEM SET "_use_adaptive_log_file_sync"=FALSE; ALTER SYSTEM SET "_use_adaptive_log_file_sync"=FALSE scope=sfile sid='*';
修改后,数据库等待事件已经变为正常的应用日常的等待事件了:
INST_ID EVENT COUNT(*)
---------- ---------------------------------------------------------------- ----------
1 db file parallel write 1
1 direct path write temp 1
1 DBWR slave I/O 1
1 SQL*Net message to client 2
1 direct path read temp 3
1 read by other session 18
1 db file sequential read 70
1 enq: TX - index contention 118
8 rows selected.
Elapsed: 00:00:00.01
SQL> /
INST_ID EVENT COUNT(*)
---------- ---------------------------------------------------------------- ----------
1 db file parallel write 1
1 direct path write temp 1
1 buffer busy waits 1
1 SQL*Net message to client 2
1 direct path read temp 3
1 DBWR slave I/O 4
1 log file sync 9
1 read by other session 12
1 enq: TX - index contention 35
1 db file sequential read 67
SQL>
此时的AWR看到,系统负载已经降下来了:
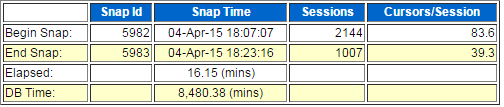
该应用正常时间,数据库连接数如下:
INST_ID MACHINE COUNT(*)
---------- ------------------------- ----------
1 800BEST\CLIENTLOG01 1
1 800BEST\LUNARSET01 43
1 800BEST\LUNARSET102 76
1 800BEST\TERMINAL 2
1 800BEST\WX01 57
1 IIS APPPOOL\LUNARSET01 5
1 IIS APPPOOL\LUNARSET02 666
1 IIS APPPOOL\LUNARSETBAK01 64
1 LUNARDB 1
9 rows selected.
SQL> /
INST_ID MACHINE COUNT(*)
---------- ------------------------- ----------
1 800BEST\CLIENTLOG01 1
1 800BEST\LUNARSET01 43
1 800BEST\LUNARSET102 76
1 800BEST\TERMINAL 3
1 800BEST\WX01 56
1 IIS APPPOOL\LUNARSET01 5
1 IIS APPPOOL\LUNARSET02 450
1 IIS APPPOOL\LUNARSETBAK01 64
1 LUNARDB 1
故障暂时缓解了,应用反映已经正常,但是可以看到,上面的信息告诉我们,对于这个应用来说,需要调整的地方还很多:
1,系统参数全面检查
2,SQL优化(SQL语句的写法,index,统计信息检查等)
3,系统IO(比如系统IO的配置,数据库filesystem_io的配置等等)
4,控制文件的检查(我一直怀疑这个有问题)
5,enq: TX – index contention
不过目前日程已经安排到5月底了,估计这个事情如果不太着急的话,应用先自己tuning,等到6月份,如果需要我再介入吧,O(∩_∩)O哈哈~。

